Deploy¶
- Flask
- metodo POST
- Persistencia: joblib
- Streamlit
- Cloud
- PAAS: StreamlitCloud
- IASS: EC2 (AWS)
- Serverless: Lambdas (AWS)
Nuestro objetivo es poner en produccion nuestro modelo, esto significa disponibilizarlo en una red interna o externa. De esta manera nuestro modelo deberia tomar el lugar de un servidor que recibe peticiones y responde predicciones.
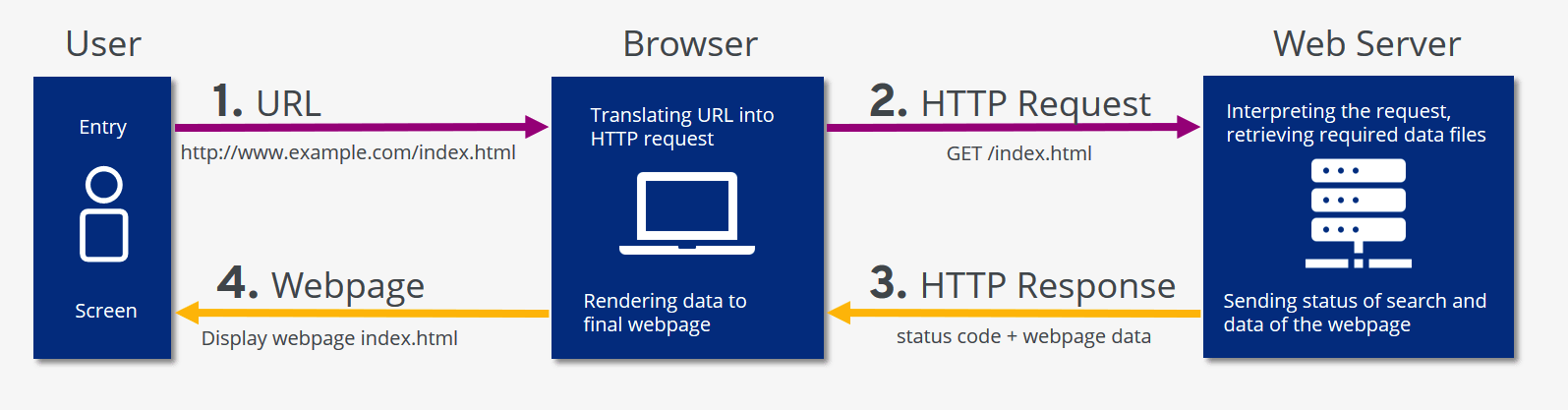
Nuestro primer servidor usando Flask:¶
Nos permite 'apificar' nuestro modelo (en realidad cualquier script de python).
Como ejemplo podemos generar un servidor para un sitio muy sencillo:
#00_flask.py
from flask import Flask
app = Flask('primersitio')
@app.route('/')
def index():
return 'Hola mundo!'
app.run(debug=True, port=8000)
Para que funcione debemos guardar el codigo en un archivo 00_flask.py.py
y luego correrlo en la consola: python 00_flask.py.
Para probar que este funcionando abrimos un navegador e ingresamos 127.0.0.1:8000
Ahora creemos un servidor que reciba parametros.¶
La idea es crear un servidor que reciba peticiones GET con parametros.
Para probarlo recordemos que desde el navegador de nuestra compu podemos enviar un GET, simulando que somos el cliente.
Repaso metodo http GET¶
GET es el metodo HTTP mas comun, habran notado que navegando por la internet los siguiente:
www.ejemplo.com/demo_form.php?name1=value1&name2=value2
En la URL del request estan los parametros del pedido.
- GET requests can be cached
- GET requests remain in the browser history
- GET requests can be bookmarked
- GET requests should never be used when dealing with sensitive data
- GET requests have length restrictions
- GET requests are only used to request data (not modify)
En este es una simple servidor que responde el cuadrado de la variable input 'a':
##01_flask_get.py
from flask import Flask, jsonify, request
app = Flask('Servidor Get') #nombre de la app
@app.route('/',methods=['GET']) #metodo http que va a usar
def funcionprincipal():#no importa el nombre el decorador se encarga
# obtengo los datos del request que viene de la peticion externa
data=request.args.to_dict() # (el metodo to_dict lo transforma en un diccionario)
try:# uso try por si no me envian una variable a
resp='el cuadrado de a es : '+str(int(data['a'])*int(data['a']))
except:
resp='no se envio la variable a'
return(resp)
app.run(host='127.0.0.1', port=5002 )# host local puerto el que quieras
Para que funcione debemos guardar el codigo en un archivo 01_flask.py
y luego correrlo en la consola python 01_flask.py.
http://127.0.0.1:5002/?a=4
http://127.0.0.1:5002/?a=4&b='asdfasf'
http://127.0.0.1:5002/?c=4&b='asdfasf'
Y si quisiera pasarle un vector?
- http://127.0.0.1:5002/?a=['1','12']
Con el metodo GET es muy dificil o imposible enviar informacion. Necesitamos usar el metodo POST.
POST Method¶
el metodo POST se usa para enviar informacion al servidor para crear o actualizar algun recurso.
en esta caso la data enviada al servidor con POST viaja en el cuerpo del request:
POST /test/demo_form.php HTTP/1.1
Host: w3schools.com
name1=value1&name2=value2
POST is one of the most common HTTP methods.
- POST requests are never cached
- POST requests do not remain in the browser history
- POST requests cannot be bookmarked
- POST requests have no restrictions on data length
- Los requests POST no se pueden hacer desde un navegador
##02_flask_post.py
from flask import Flask, jsonify, request
app = Flask('server post')
@app.route('/',methods=['POST']) #aca definimos q recibe requests POST
def predict(): #la funcion q se ejecuta
data = request.get_json(force=True)
try:
a_vector = np.array(data['a']).astype('int')
# Le damos forma de un diccionario para poder hacer el traspaso a json trivialmente
a_2=a_vector**2
resp={'response' : a_2.tolist() }#importante pasar a lista los numpy arrays
except:
resp={'response' : 'no esta presente la variable a'}
# en esta linea, transformamos el diccionario en json con jsonify (funcionalidad de flask)
# este json es incorporado en el cuerpo de la respuesta
return jsonify(resp)
app.run(host='127.0.0.1', port=5001)
Queremos pasar la variable 'a' como un vector, con el metodo POST es muy sencillo. Tenemos dos opciones para hacer este metodo POST, usando requests desde python o usando POSTMAN.
Requests POST¶
import requests as req
import json
# parametros, la url y un diccionario
url='http://127.0.0.1:5002/'# <--- url por default en servidor
data = { 'a': ['1', '-2', '4', '13', '5', '0', '10', '1'] , 'b' : 2342 }
# el requests
r = req.post(url, json=data)
r
<Response [200]>
r.json()
{'response': [1, 4, 16, 169, 25, 0, 100, 1]}
r.json()['response']
[1, 4, 16, 169, 25, 0, 100, 1]
type(r.json()['response'])
list
type(r.json()['response'][0])
int
En general tendran la forma:
from flask import Flask, jsonify, request
app = Flask('Nombre')
@app.route('/',methods=['POST'])
#defino la funcion que manejarara el request
def predict():
# obtengo los datos del request post
data = request.get_json(force=True)
###
### cositas lindas
###
return jsonify(resp)
app.run(host='127.0.0.1', port=5001)
Debugeando¶
Este modo nos permite que la app se ejecute nuevamente cada vez que el archivo miapp.py sea modificado. Nos permite poder ir cambiando el codigo si es que algo no funciona bien, ayuda poner algunos print en el codigo lo que se vera en la consola donde este corriendo la app.
from flask import Flask, jsonify, request
app = Flask('Nombre')
@app.route('/',methods=['POST'])
def predict():
data = request.get_json(force=True)
return jsonify(resp)
app.run(host='127.0.0.1', port=5001, debug=True)
Flask + Plotly¶
Esta app de Flask genera una pagina con un grafico de Plotly con el cual podemos interactuar! Vamos a armar un grafico con los datos de contagios de covid-19 para diferentes paises. Usamos requests GET asi el usuario puede mandar la informacion del pais del cual quiere ver los datos en la URL
##03_flask_plotly.py
from flask import Flask, render_template
from flask import jsonify, request
import pandas as pd
import json
import plotly
import plotly.express as px
import requests as req
import numpy as np
app = Flask(__name__)
@app.route('/',methods=['GET'])
def notdash():
params=request.args.to_dict()
paises=json.loads(params['paises'].replace('\'', '"'))
tipo=json.loads(params['tipo'].replace('\'', '"'))
fig = px.line(title=tipo)
for pais in paises:
r=req.get('http://corona-api.com/countries/' + pais)
t=[]
casos=[]
muertes=[]
data=r.json()
for day in data['data']['timeline']:
t.append(day['date'])
casos.append(day['new_confirmed'])
muertes.append(day['new_deaths'])
df=pd.DataFrame()
df.index=pd.to_datetime(t)
df['casos']=casos
df['muertes']=muertes
pop=data['data']['population']/100000
df['casos_100k']=np.array(casos)/pop
df['muertes_100k']=np.array(muertes)/pop
fig.add_scatter(x=df.index, y=df[tipo],name=pais,mode='markers+lines')
graphJSON = json.dumps(fig, cls=plotly.utils.PlotlyJSONEncoder)
return render_template('notdash.html', graphJSON=graphJSON)
app.run(debug=True)
Podemos probarla en:
- http://127.0.0.1:8000/?paises=['BO','CH','ES']&tipo='muertes_100k'
- http://127.0.0.1:8000/?paises=['AR','FR','ES']&tipo='casos_100k'
Para el codigo de los paises hay que usar:
https://en.wikipedia.org/wiki/ISO_3166-1_alpha-2
Persistencia¶
Ahora que ya sabemos como podemos disponibilizar nuestro codigo, implementemos un servidor que devuelva predicciones de un modelo pre-entrenado. No es eficiente generar un servidor que con cada peticion vuelva a entrenar el modelo. Necesitamos de alguna manera guardar el modelo entrenado, hasta ahora solo guardamos .csv o notebooks.
Pickle / Joblib¶
Pickle es una libreria que nos permite guardar un modelo entrenado (o casi cualquier objeto de python) en un archivo para ser reutilizado cuando quieras. Es por esto que jamas hay que manipular pickles que no sabemos su origen.
Joblib es una libreria que hace mas facil el uso de pickle:
from joblib import dump, load
dump(model,'elmodelo.joblib')
#persistencia.py
import pandas as pd
from sklearn.linear_model import LogisticRegression
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.model_selection import train_test_split
import numpy as np
df=pd.read_csv('amazon.csv')
X_train, X_test, y_train, y_test = train_test_split(df['Reviews'],
df['Positivos'],
random_state=0,
stratify=df['Positivos'])
vect = CountVectorizer(min_df=5, ngram_range=(1,2)).fit(X_train)
X_train_vectorized = vect.transform(X_train)
model = LogisticRegression(max_iter=5000)
model.fit(X_train_vectorized, y_train)
from joblib import dump, load
dump([model,vect], 'model_vect.joblib')
Vamos a cargar el modelo entrenado desde otro kernel de python:
from joblib import load
model,vect = load('model_vect.joblib')
type(model),type(vect)
(sklearn.linear_model._logistic.LogisticRegression, sklearn.feature_extraction.text.CountVectorizer)
print(model.predict(vect.transform(['not an issue, phone is working',
'an issue, phone is not working'])))
[1 0]
Flask+Pickle¶
Ahora generemos una API que utilice un modelo pre-entrenado, vamos a generar un endpoint para requests POST asi nos pueden enviar varios texto para ser clasificados.
## 05_flask_joblib.py
from flask import Flask, jsonify, request
from joblib import dump, load
model,vect = load('model_vect.joblib')
app = Flask('Nombre')
@app.route('/',methods=['POST'])
def predict():
# obtengo los datos del request post
data = request.get_json(force=True)
texto=data['texto']
resp=model.predict(vect.transform([texto]))
return jsonify(resp.tolist())
app.run(host='127.0.0.1', port=5001)
# parametros, la url y un diccionario
import requests as req
url='http://127.0.0.1:5001/' # <--- url por default en servidor
data = { "texto": "the battery died after two weeks, very disapointed" }
# el requests
r = req.post(url, json=data)
r
<Response [200]>
r.json()
[0]
req.post(url, json={ "texto": "it fits my needs" }).json()
[1]
req.post(url, json={ "texto": " it was very dificcult to understand the manual" }).json()
[0]
Streamlit¶
Flask tiene la gran desventaja que solo se puede interactuar mediante requests.
Streamlit es un framework para crear web-apps de una manera super sencilla y dinámica.
Todos los elementos de una página web son definidos en un script de python. Cada uno será definido por una función y a medida que los agregamos podemos ver su resultado en una página de nuestro navegador.
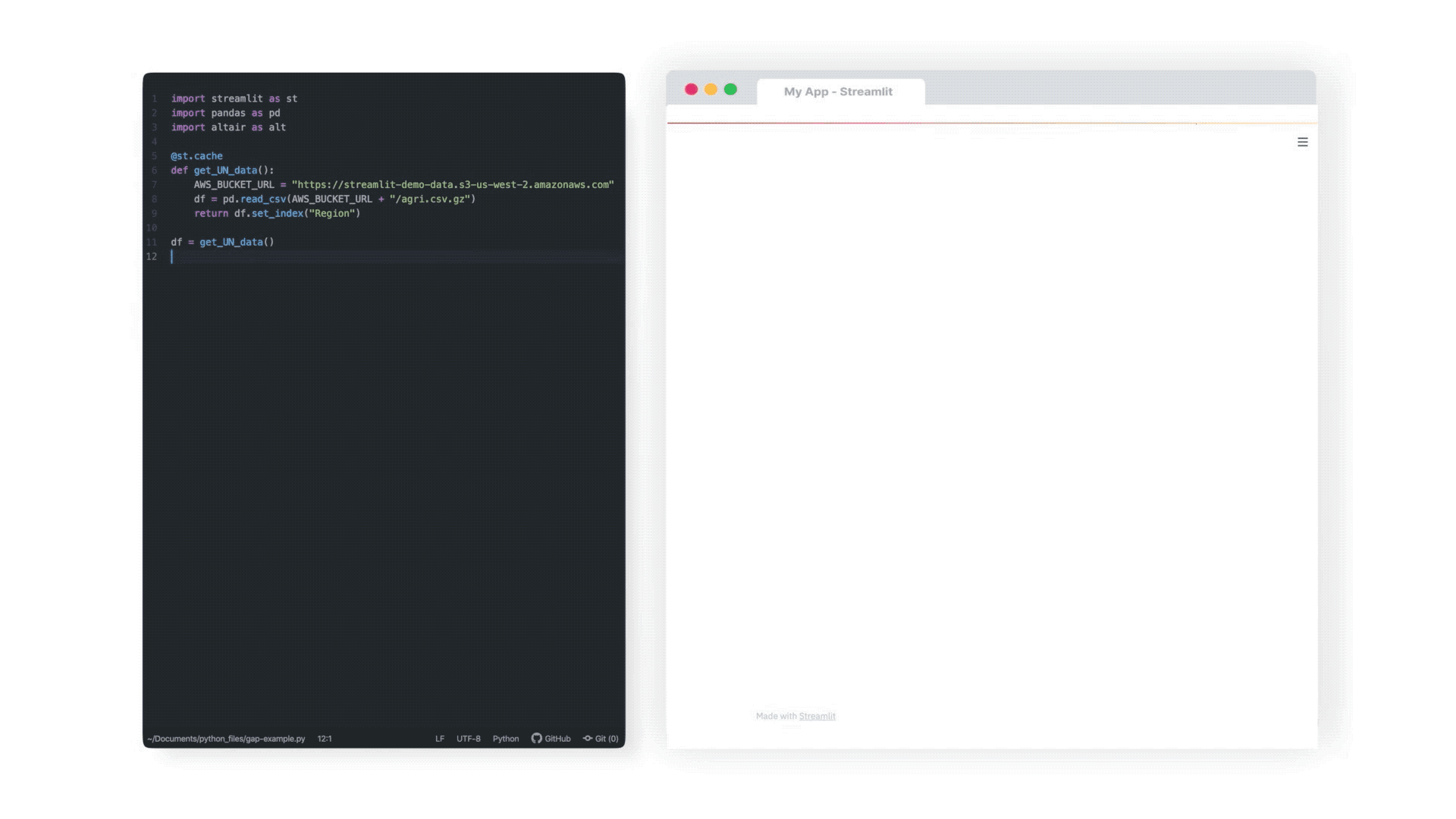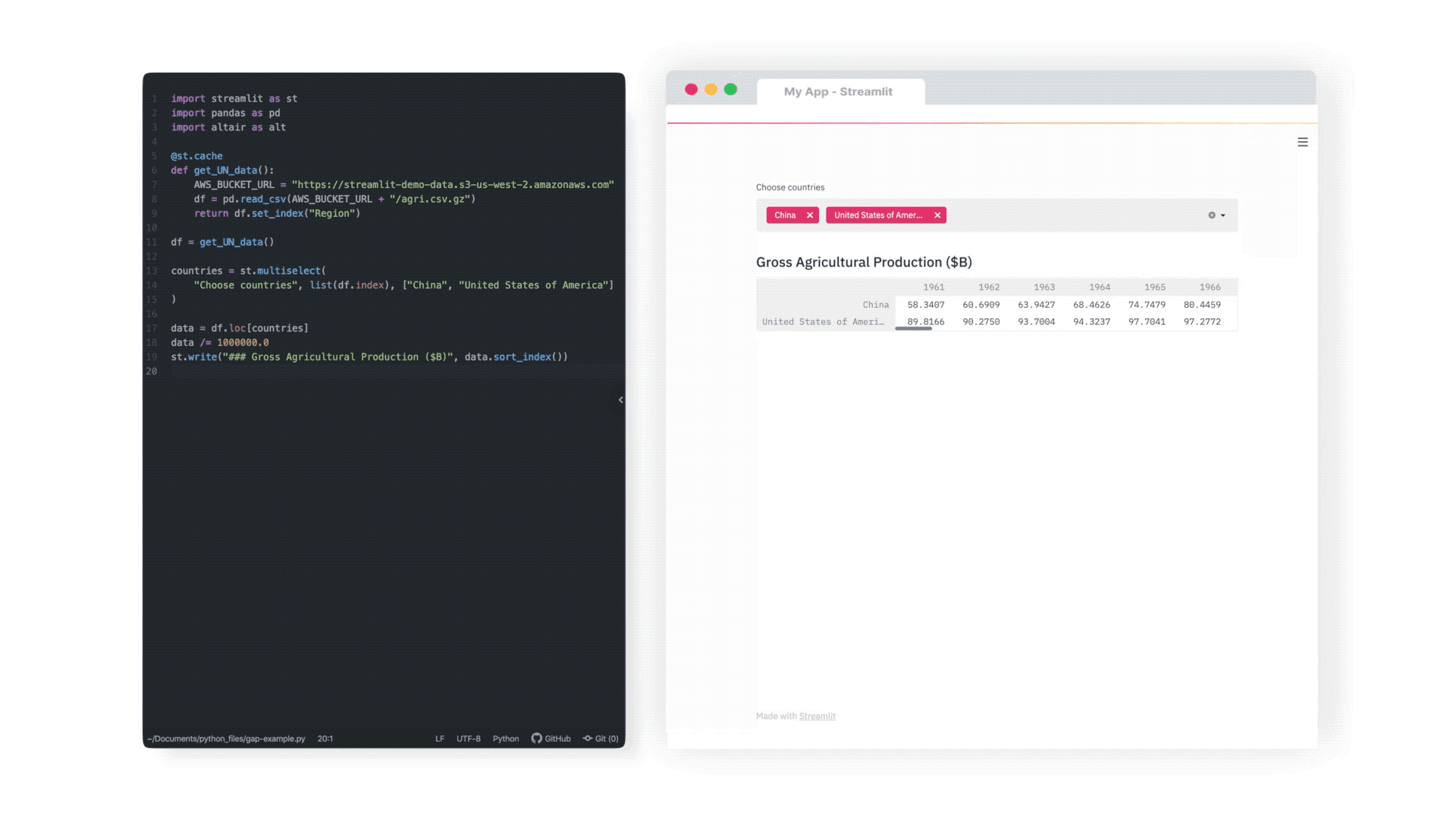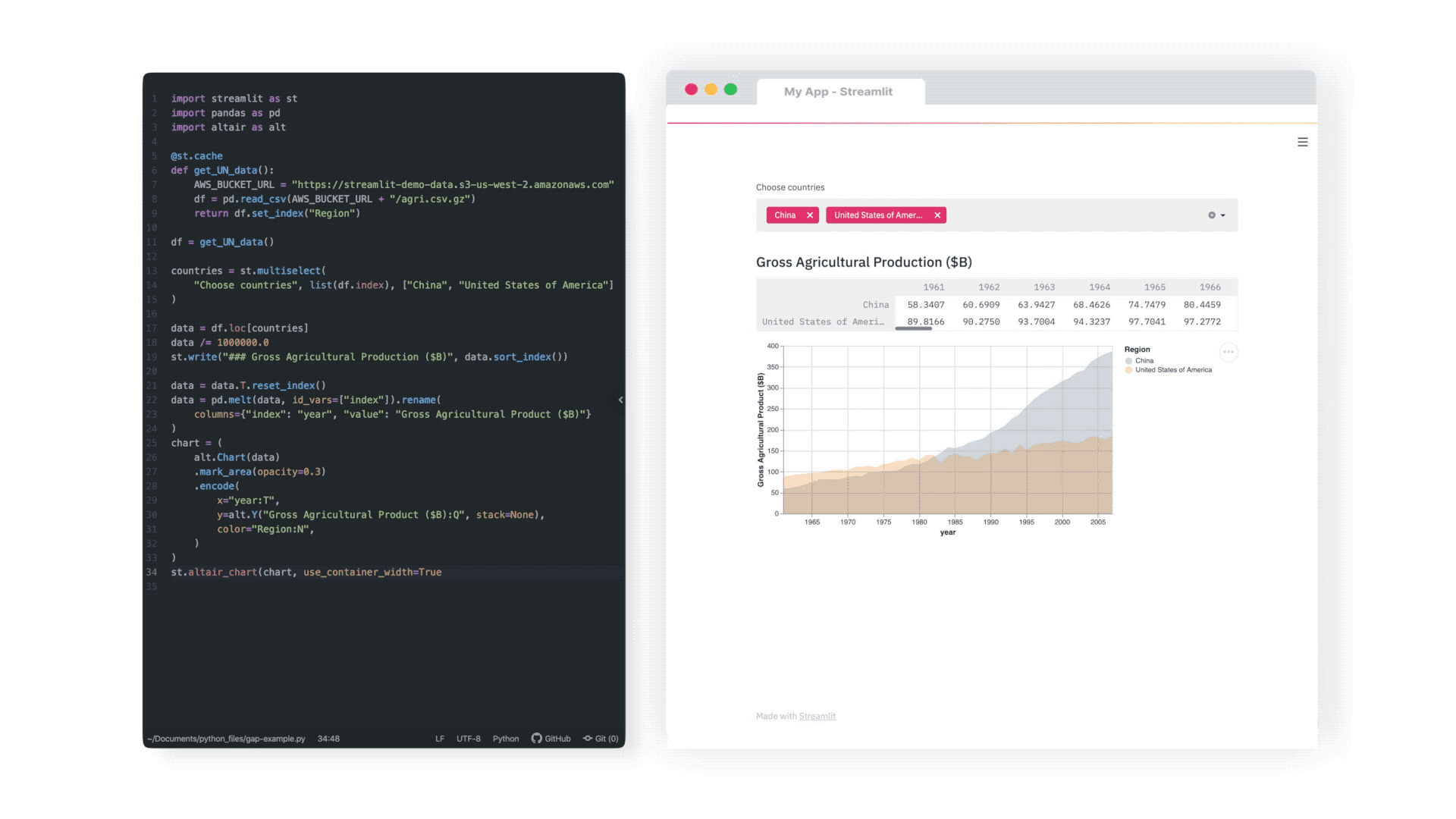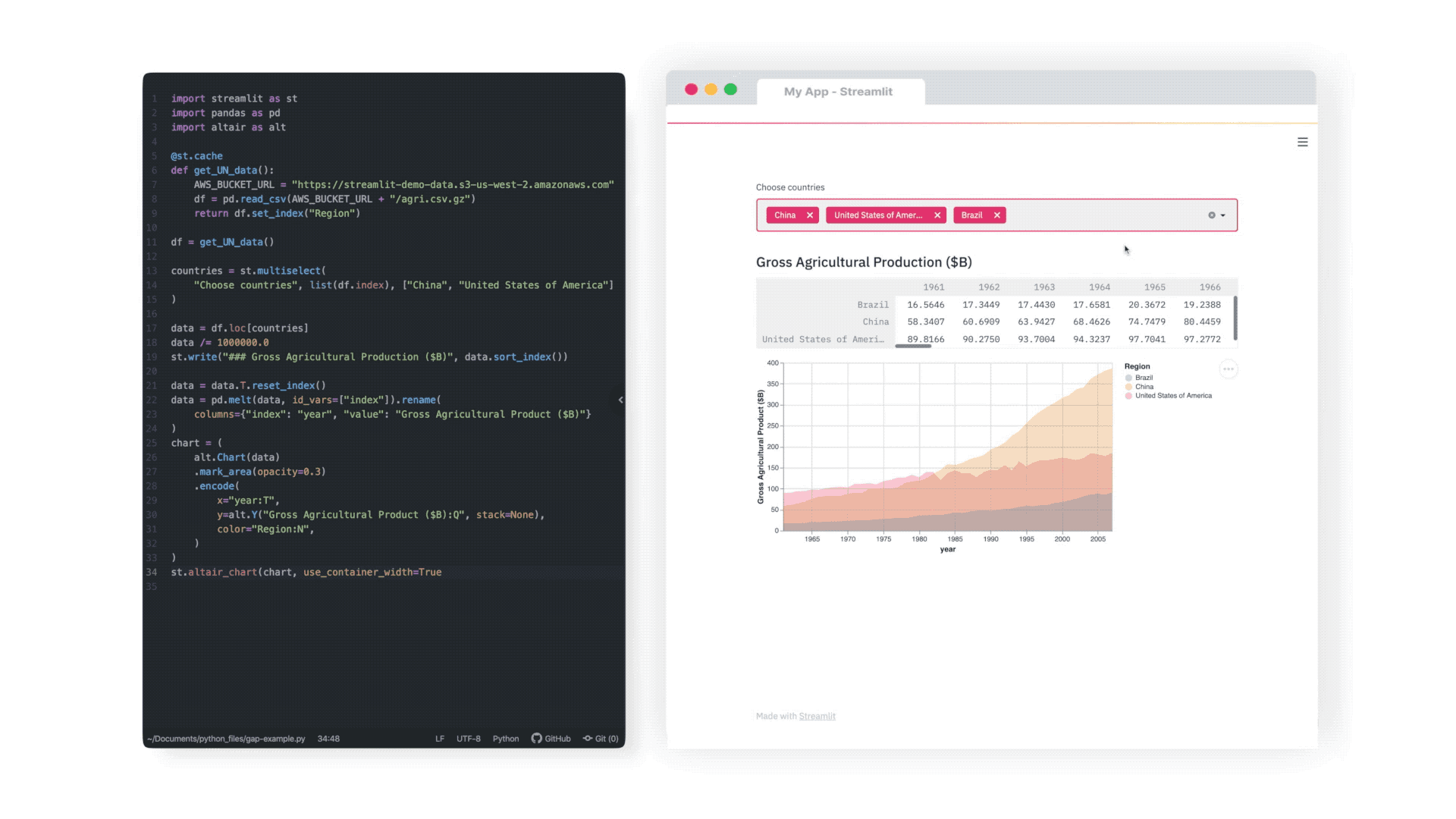
import streamlit as st
x=st.slider('eleji valor')
st.write('el cubo de ',x , ' es', x*x*x)

https://www.streamlit.io/
Las apps de Streamlit son scripts de python que se ejecutan secuencialmente.
Cada vez que un usuario accede a la app, el script se re ejecuta.
Duran la ejeccion, Streamlit muestra el output en el navegador.
Cada interaccion con un widget hace que el script se re-ejecute con el nuevo valor del widget.
Se puede usar cache para evitar recalcular funciones muy pesadas, mejorando el tiempo de respuesta de la app.
Widgets de Streamlit¶
Los widgets son objetos que sirve para que el usuario interactue con los datos o el modelo, hay una extensa lista:
https://docs.streamlit.io/en/stable/api.html
Ejemplo:
import streamlit as st
x = st.slider('x') # 👈 widget
st.write(x, 'squared is', x * x)
En este ejmeplo la app tira un output “0 squared is 0”. Cada vez que el usuario interactua , Streamlit vuelve a ejecutar el script entero, asignando el nuevo valor a la variable asociadad al widget. Si fuera 10, Streamlit corre el codigo y daria como output “10 squared is 100”.
Componentes¶
widgets developeados por la comunidad que extienden la funcionalidad de Streamlit.
https://www.streamlit.io/components
##04_streamlit_plotly.py
import streamlit as st
import pandas as pd
import numpy as np
import plotly.express as px
import requests as req
paises = st.multiselect(
'Paises a visualizar:',
['AR', 'BR', 'CH', 'UY','BO'])
# texto
option = st.selectbox(
'Que datos desea visualizar?',
('casos_100k','muertes_100k'))
tipo=option
if st.button('plot'):
fig = px.line(title=tipo)
for pais in paises:
r=req.get('http://corona-api.com/countries/' + pais)
t=[]
casos=[]
muertes=[]
data=r.json()
for day in data['data']['timeline']:
t.append(day['date'])
casos.append(day['new_confirmed'])
muertes.append(day['new_deaths'])
df=pd.DataFrame()
df.index=pd.to_datetime(t)
df['casos']=casos
df['muertes']=muertes
pop=data['data']['population']/100000
df['casos_100k']=np.array(casos)/pop
df['muertes_100k']=np.array(muertes)/pop
fig.add_scatter(x=df.index, y=df[tipo],name=pais,mode='markers+lines')
st.plotly_chart(fig)
else:
pass
Guardamos todo el codigo en un archivo ".py" y luego lo ejecutamos desde la consola:
streamlit run miarchivito.py
en consola deberiamos ver la url de nuestra app:¶
http://192.168.0.18:8501
Hola mundo?¶
Como disponibilizo lo que estuvimos haciendo para que puede ser usado por cualquier persona de la internet?
Dos opciones:
En mi Compu:
Firewalls
Llamar a fibertel para que abran puertos o habiliten una DMZ
Peligroso
Siempre tiene que estar corriendo la terminal de python
En la nube:
Cloud computing¶

Heroku (era gratis hasta nov 2022)¶





Streamlit Cloud (gratis nov 2022)¶
https://streamlit.io/cloud
Hay que generarse una cuenta y linkear el respositorio de github donde se encuentre nuestro proyecto.
En el repositorio ademas del archivo mi_streamlit_app.py tiene que haber un archivo llamado requirements.py con todas las librerias que usamos en nuestro proyecto y sus respectivas versiones.
Ejemplo:
numpy==1.20
matplotlib==3.4.2
pandas==1.3.0
scikit-learn==0.24.2
Esta app de streamlit:
https://github.com/carabedo/properatti
Esta subida aca:
https://carabedo-properatti-app-65lpet.streamlitapp.com
IAAS (infrastructure-as-a-service)¶

IAAS¶
En este esquema tenemos el control total de nuestro proyecto, tenemos a nuestra disposicion un maquina virtual para poder configurar desde 0 nuestra app/api/etc...
ORACLE Virtual Machines (gratis por siempre*)¶
Ejemplo en oracle:
Creamos una vm aca
AWS EC2 (gratis por un año)¶
Nos creamos una cuenta en https://aws.amazon.com con una tarjeta de credito tenemos acceso a un año de recursos gratuitos (FREE TIER). Entre ellos estan las EC2.
AWS EC2¶
Algunos consejos:
- Crear una nueva llave para el login (elegir un nombre que te acuerdes) guardar el archivo.
- Crear una maquina virtual usando una imagen UBUNTU, traten de evitar AMAZON LINUX.
- Crear un grupo de seguridad usando un nombre facil de recordar
- Asignarle 30 GB (maximo para la FREE TIER) en vez del 8 GB default.
AWS EC2¶
Cuando creamos una instancia EC2 lo mas importante que tenemos que saber para poder usarla es:
- IP: Numero que identifica a la vm en la internet.
- Usuario: Nombre del usuario en el servidor, siempre es el mismo (ubuntu)
- key: Archivo con nuestras credenciales.
Como accedemos y controlamos la VM?¶
SSH¶
ssh es un programa por consola que me permite conectarme de manera segura a otra computadora. Basicamente es como si pudieramos abrir una consola en la computadora remota. Tenemos control total.
Primero necesitamos cambiarle los permisos a la llave que nos bajamos, desde una consola de unix:
chmod 400 <private_key_file>
Para que esta linea no tire error debemos estar parados en la misma carpeta del archivo .pem que se nos descargo cuando creamos la vm.
Recuerden que nos podemos mover entre carpetas por consola usando el comando cd.
Luego de haber cambiado los permisos del archivo ya nos podemos conectar a una terminal de la maquina virtual usando la llave:
ssh -i <private_key_file> <username>@<public-ip-address>
En mi caso:
ssh -i sshtest.key opc@193.123.101.232
Luego de haber cambiado los permisos del archivo ya nos podemos conectar a una terminal de la maquina virtual usando la llave y la ipv4 publica (esto esta en el dashboard de aws):
El usuario por default es ubuntu, lo dejamos asi y nos conectamos desde una consola de nuestra compu:
ssh -i ec2_test2.pem ubuntu@52.23.241.1
shh -i pathdelallave ubuntu@ipv4publica
Le damos ok si sale alguna pregunta.
SSH¶
Creemos una carpeta:
mkdir prueba
Entremos en la carpeta y creemos un archivo con codigo en python
cd prueba
vim prueba.py
En vim escribamos algo sencillo:
import numpy as np
print(np.pi)
Ejecutemos nuestro script:
python3 prueba.py
Que paso?
Instalando librerias¶
Oracle¶
Instalamos conda:¶
es una VM vacia, necesitamos instalar todas las librerias que vamos a usar
wget https://repo.continuum.io/miniconda/Miniconda3-latest-Linux-x86_64.sh
sh Miniconda3-latest-Linux-x86_64.sh
AWS¶
sudo apt update
sudo apt install python3-pip
Ahora instalamos cualquier libreria usando por ejemplo:
pip3 install numpy
Subiendo archivos¶
Desde una consola local usamos el programita scp (secure copy):
scp -i key.pem -r /path/local/files root@:0.0.0.0:/path/on/my/server
Necitamos la ip publica del servidor, en nuestro caso quedaria asi:
scp -i sshtest.key ./server_bokeh.py opc@193.123.101.232:/home/opc/prueba
Esto subiria el archivo server_bokeh.py a la maquina virtual a una carpeta llamada prueba. Solo funciona si ejecuto el comando en la misma carpeta donde se encuentra dicho archivo y la llave.
Subiendo carpetas¶
- -r recursivamente la carpeta templates
scp -i sshtest.key -r ./templates/ opc@193.123.101.232:/home/opc/prueba
ssh con visualcode¶
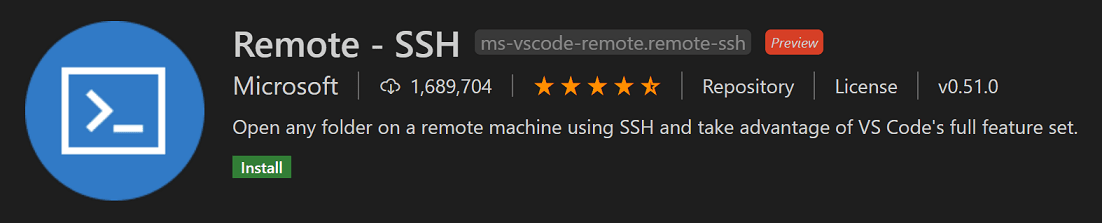

Hay que editar el archivo que guarda la direccion de las maquinas virtuales y la ubicacion en nuestra compu de las llaves. En Host ponemos el nombre que queremos, HostName es la ip de la maquina, luego el path de la .key en nuestra compu y por ultimo el nombre del usuario en la maquina virtual para las vms de oracle es opc.
Host Oracle
HostName 193.123.110.190
IdentityFile /Users/fernando/gits/deploy/sshtest.key
User opc
No importa en que plataforma tenemos nuestra maquina virtual, solo necesitamos la ip publica, una llave y saber el nombre de nuestro usuario.
Host EC2
HostName 52.23.241.1
IdentityFile /Users/fernando/Downloads/ec2_test2.key
User ubuntu
Subiendo archivos¶
- Usando vscode podemos arrastrar desde nuestra compu o crear los archivos en el vscode.
- Otra opcion es usar git desde la consola remota:
git clone https://github.com/carabedo/deploy_tests.git
Flask en una vm (oracle)¶
- levantemos un servidor de flask en nuestra vm, guardamos el codigo en
app.py.
flask run --host=0.0.0.0
- abrimos el puerto donde esta flask:
sudo iptables -I INPUT 6 -m state --state NEW -p tcp --dport 5000 -j ACCEPT
- agregamos una
Ingress Rulesen laSecurity Listde la subnet asociada a nuestra VM desde la pagina de oracle.
ahora nuestra 'app' es accesible desde cualquier maquina
- http://193.123.110.190:5002/?a=4
Flask en una vm (aws)¶
Primero corramos nuestra app mas sencilla:
python3 00_flask.py
Si hicimos todo bien, cualquier con una conexion a internet deberia poder acceder a nuestra pagina. Pero como lo hace? Necesitamos la url/ip publica de esta vm.
Public IPv4 DNS mi VM (va a cambiar para ustedes): ec2-52-23-241-1.compute-1.amazonaws.com
Ahora si, nuestra pagina deberia estar en:
http://ec2-52-23-241-1.compute-1.amazonaws.com:8000
Security Groups¶
AWS nos permite controlar el trafico de ingreso y egreso a nuestra vm, generamos una regla para que puedan ingresar nuestros requests, por cualquier puerto desde cualquier ip:
EC2 > Security Groups > edit Inbound Rules
Add Rule > ALL TCP > anywhere IPv4 > SAVE
http://ec2-52-23-241-1.compute-1.amazonaws.com:8000
Flask+plotly en una vm¶
Para esta app debemos instalar las librerias necesarias en el servidor/vm:
pip3 install pandas
pip3 install plotly
Desde la consola levantamos el servidor
python3 03_flask_plotly
- http://ec2-52-23-241-1.compute-1.amazonaws.com:8000/?paises=['AR','FR','ES']&tipo='muertes_100k'
Flask+Joblib (AWS)¶
Levantemos nuestra modelo de clasificacion de texto:
python3 flask_joblib.py
Seguramente nos pida instalar sklearn.
# Una vez funcionando el servidor lo probamos haciendo un requests post
import requests as req
req.post('http://ec2-35-175-182-254.compute-1.amazonaws.com:5001', json={ "texto": "it fits my needs" }).json()
[1]
Si cierro la sesion ssh el modelo deja de funcionar, volvemos a lo mismo de antes. Necesito que quede corriende indefindamente.
Screen¶
Un programita para la consola que nos permite cerrar la consola sin que nuestro servidor deje de funcionar.
Nos conectamos desde una consola de linux/macos:
ssh -i ec2_test2.pem ubuntu@52.23.241.1
Instalamos screen:
- oracle:
sudo yum install screen - aws:
sudo apt-get install screen
Iniciamos la sesion:
screen -S misesion
Abrimos el servidor:
python3 flask_joblib.py
Y ahora poder cerrar la consola local sin cerrar la remota:
Clrl+A y luego apretamos la tecla d.
Ya podemos cerrar nuestra consola local\vscode.
Para volver a conectarnos a la sesion, abrumos una consola, hacemos ssh y luego:
Con screen -ls vemos las sessiones abiertas. Deberiamos ver misesion.
Con screen -r misesion nos volvemos a conectar
De esta manera puedo dejar corriendo el servidor remoto y cerrar la consola local. Pudiendo reconectarme cuando quiera.
Para cerrar una sesion:
screen -XS misesion quit
Para cerrar todas las sesiones:
killall screen
#probamos el servidor (funciona)
req.post('http://ec2-35-175-182-254.compute-1.amazonaws.com:5001', json={ "texto": "it fits my needs" }).json()
[1]
Hacemos ssh al servidor, cerramos la sesion:
ssh -i ec2_test2.pem ubuntu@52.23.241.1
screen -XS misesion quit
# luego de cerrar la sesion, deja de funcionar
req.post('http://ec2-35-175-182-254.compute-1.amazonaws.com:5001', json={ "texto": "it fits my needs" }).json()
ConnectionError: HTTPConnectionPool(host='ec2-35-175-182-254.compute-1.amazonaws.com', port=5001): Max retries exceeded with url: / (Caused by NewConnectionError('<urllib3.connection.HTTPConnection object at 0x14c89df10>: Failed to establish a new connection: [Errno 61] Connection refused'))
Serverless¶

Lambdas (aws)¶
A diferencia de la EC2 las lambdas son funciones como servicio, en este caso AWS ofrece el poder de computo para una funcion que puede estar escrita en varios lenguajes. Esto puede resultar mas barato y mas sencillo de configurar (o no), ya que solo nos preocupamos por el codigo.
Esta modalidad reduce los costos ya que no es necesario tener una vm prendida 24/7 exclusivamente para tal vez utilizarla una cantidad limitada de veces. Miles de lambdas son ejectudas sobre una sola vm haciendo mas eficiente el consumo de recursos.
Nuestra primer Lambda¶
- Creamos una lambda usando el runtime de
python3.9 - Generamos un nuevo rol para esta lambda
- Habilitamos 'Function URL' sin authentification.
- Como code source copiamos lo siguiente y le damos a 'deploy':
import json
def lambda_handler(event, context):
# TODO implement
return {
'statusCode': 200,
'body': json.dumps('Hola ya cree una lambda!')
}
Si todo salio bien deberian tener una lambda (con otra url) parecida a esta:
https://fdejkcwkzs55buhjmgij6naode0ycaqo.lambda-url.us-east-1.on.aws/
Cambiemos el codigo a:¶
import json
import numpy as np
def lambda_handler(event, context):
body = json.loads(event['body'])
x=np.array(body['x'])
y=x**2
result=[{'body' : body, 'y' : y.tolist(), 'name' : 'cuadratica'}]
return {
'statusCode': 200,
'body': json.dumps(result)
}
Si intentamos usar numpy no vamos a poder, necesitamos de alguna manera instalar librerias.
Layers¶
Como instalo librerias si esto no es una vm? pip? No hace falta, se puede reutilizar entornos:
https://github.com/keithrozario/Klayers
arn:aws:lambda:us-east-1:770693421928:layer:Klayers-p39-numpy:8
import numpy as np
data={"x": np.array([1,2,3,4]).tolist()}
respuesta=req.post('https://loge3xqqqreddmhnl463w5gl3y0otllj.lambda-url.us-east-1.on.aws/',json=data)
respuesta
<Response [200]>
respuesta.json()
[{'body': {'x': [1, 2, 3, 4]}, 'y': [1, 4, 9, 16], 'name': 'cuadratica'}]
type(respuesta.json()[0]['y']),type(respuesta.json()[0]['y'][0])
(list, int)
import pandas as pd
df=pd.read_csv('https://raw.githubusercontent.com/carabedo/labs/master/data/freddo.csv')
df
| temp | venta | |
|---|---|---|
| 0 | 12.2 | 125 |
| 1 | 14.4 | 175 |
| 2 | 15.0 | 325 |
| 3 | 16.7 | 275 |
| 4 | 17.8 | 425 |
| 5 | 18.3 | 400 |
| 6 | 19.4 | 450 |
| 7 | 22.2 | 425 |
| 8 | 22.8 | 450 |
| 9 | 23.9 | 525 |
| 10 | 25.0 | 550 |
| 11 | 26.7 | 625 |
data={'x': df.values.tolist()}
respuesta=req.post('https://loge3xqqqreddmhnl463w5gl3y0otllj.lambda-url.us-east-1.on.aws/',json=data)
respuesta
<Response [200]>
respuesta.json()[0]['y']
[[148.83999999999997, 15625.0], [207.36, 30625.0], [225.0, 105625.0], [278.89, 75625.0], [316.84000000000003, 180625.0], [334.89000000000004, 160000.0], [376.35999999999996, 202500.0], [492.84, 180625.0], [519.84, 202500.0], [571.2099999999999, 275625.0], [625.0, 302500.0], [712.89, 390625.0]]
type(respuesta.json()[0]['y']),type(respuesta.json()[0]['y'][0]),type(respuesta.json()[0]['y'][0][0])
(list, list, float)
Lambdas+sklearn+joblib+s3¶
El ultimo esfuerzo, quiero disponibilizar el clasificador de texto usando una lambda, todo seria parecido, deberiamos buscar layers para cada libreria que necesitemos:
- joblib
- sklearn
Tutorial:
https://towardsdatascience.com/super-simple-scikit-learn-apis-in-aws-301c4f3b5629
Links¶
Instalar wsl:¶
https://www.youtube.com/watch?v=-jTNQSlkw2Y
Usar wsl desde VisualStudioCode:¶
https://www.youtube.com/watch?v=bRW5r7TK6KM
setear flask en una vm:¶
https://developer.oracle.com/oracle-cloud-infrastructure/compute-vm-simple-tutorial/ https://docs.oracle.com/es-ww/iaas/developer-tutorials/tutorials/flask-on-ubuntu/01oci-ubuntu-flask-summary.html
instalar conda en oracle linux 7¶
https://deeplearning.lipingyang.org/2018/12/24/install-miniconda-on-centos-7-redhat-7/