
Agenda¶
Text minning como un problema de aprendizaje no supervisado
Reduccion de la dimensionalidad
SVD TSNE
Clustering
Text minning como un problema de aprendizaje supervisado
- Clasificacion
Embeddings

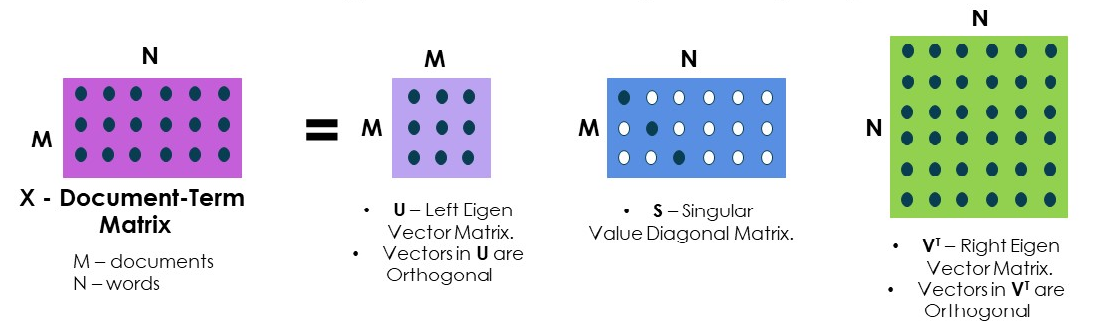
Singular Value Decomposition (SVD)¶
SVD es una técnica (general) de factorización de matrices.
Comprender la matemática involucrada excede las ambiciones de esta presentación. Para indagar en ella pueden consultar alguna de estas referencias:
Practical Text Mining and Statistical Analysis for Non-structured Text Data Applications 2012, Chapter 11.
https://en.wikipedia.org/wiki/Singular_value_decomposition
En particular en text mining usamos SVD para reducir la dimensionalidad del corpus de texto que, a diferencia de lo que hemos hecho hasta ahora, no consiste en remover elementos (stopwords, etc), sino en encontrar combinaciones de palabras que resulten informativas y quedarnos con "las mejores" de éstas.
Una analogía posible es la siguiente:
Podemos describir un rectángulo dando dos variables (features): su base y su altura.
Si quisiéramos describir el rectángulo con una sola de estas features, por ejemplo la base, estaríamos perdiendo información muy relevante ya que existen rectángulos muy diferentes con la misma base.
Sin embargo, si generáramos una nueva variable "área" igual al producto de base por altura, y describiéramos al rectángulo usando solamente el área, estaríamos reduciendo la dimensionalidad de una manera mucho más razonable, guardando más información sobre el rectángulo original que al quedarnos solo con la base.
SVD es una transformación algebraica parecida a PCA (principal component analysis) que se puede usar en el contexto de text mining para encontrar combinaciones lineales de los términos que resulten informativos, de modo que podamos describir el data set con un número de combinaciones menor al número de términos que teníamos originalmente.
Estas combinaciones pueden considerarse como dimensiones con sentido semántico latente (latent semantic dimensions), es decir, dimensiones en las que tiene sentido proyectar el dataset precisamente por su contenido semántico.
El motivo por el cual podemos reducir la dimensionalidad de los textos proyectandolos a estas latent semantic dimensions es que muchas veces existe redundancia en el conjunto de documentos. Es decir que con palabras más o menos distintas, muchos documentos hablan de los mismos temas.
En el ejemplo de los 6 textos que venimos usando
t0='El potro y el angel llegaron al cine por casualidad.'
t1= 'El ángel, el tanque del cine nacional, un paso más cerca del oscar',
t2= "final del mes del cine nacional: 'El Potro', la única cinta 'millonaria'",
t3= 'Juan Martin del potro volvió a tandil: se dio el ultimo baño de masas con los suyos.',
t4= 'Juan Martin del potro fue recibido por una multitud en Tandil.',
t5= "Juan Martin del potro fue a ver 'El Potro' al cine y le encantó."
Hay 45 palabras distintas. (Antes redujimos el número de términos a 28 quitando stopwords).
Sin embargo los textos hablan esencialmente de tres temas: hay dos películas nuevas en el cine, Del Potro visitó Tandil, Del Potro fue al cine.
Esta reducción de la dimensionalidad podría mejorar la performance de un clasificador o un modelo de clustering. Por otro lado, una reducción a dos o tres dimensiones nos puede permitir visualizar los datos.
Hay que tener en cuenta, sin embargo, que en general necesitaremos más dimensiones para describir correctamente el corpus y es posible que la representación en dos dimensiones no nos revele mucho sobre la estructura del dataset.
Las dimensiones que generamos son combinaciones lineales de los términos.
Podemos ver cuánto pesa cada término en la definición de estas dimensiones.
Ordenemos los términos en función de cuánto pesan en cada dimensión:
spanishStemmer=SnowballStemmer("spanish")
# Generamos textos
t0 = "El potro y el angel llegaron al cine por casualidad."
t1 = "El ángel, el tanque del cine nacional, un paso más cerca del oscar"
t2 = "final del mes del cine nacional: 'El Potro', la única cinta 'millonaria'"
t3 = "Juan Martin del potro volvió a tandil: se dio el ultimo baño de masas con los suyos."
t4 = "Juan Martin del potro fue recibido por una multitud en Tandil."
t5= "Juan Martin del potro fue a ver 'El Potro' al cine y le encantó."
textos=[t0,t1,t2,t3,t4,t5];
stopwords_sp = stopwords.words('spanish');
# si no hacemos esto y usamos directo stopwords_sp, CountVectorizer devuelve un warning
stopwords_sp_stem = [spanishStemmer.stem(x) for x in stopwords_sp]
vectorizer = CountVectorizer(stop_words = stopwords_sp_stem, lowercase = True, strip_accents = 'unicode');
vectorizer.fit(textos);
countvectorizer_encoding = vectorizer.transform(textos);
pd.DataFrame(countvectorizer_encoding.todense(),
columns = vectorizer.get_feature_names()) # Usamos el método .todense() para ver la matriz completa
| angel | bano | casualidad | cerca | cine | cinta | dio | encanto | final | juan | ... | paso | potro | recibido | suyos | tandil | tanque | ultimo | unica | ver | volvio | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 0 | 1 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | ... | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 1 | 1 | 0 | 0 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | ... | 1 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 |
| 2 | 0 | 0 | 0 | 0 | 1 | 1 | 0 | 0 | 1 | 0 | ... | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 |
| 3 | 0 | 1 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 1 | ... | 0 | 1 | 0 | 1 | 1 | 0 | 1 | 0 | 0 | 1 |
| 4 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | ... | 0 | 1 | 1 | 0 | 1 | 0 | 0 | 0 | 0 | 0 |
| 5 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 1 | 0 | 1 | ... | 0 | 2 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 |
6 rows × 28 columns
Tfidf_encoding=TfidfTransformer().fit_transform(countvectorizer_encoding);
pd.DataFrame(Tfidf_encoding.todense(),columns=vectorizer.get_feature_names())
| angel | bano | casualidad | cerca | cine | cinta | dio | encanto | final | juan | ... | paso | potro | recibido | suyos | tandil | tanque | ultimo | unica | ver | volvio | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0.452305 | 0.000000 | 0.551581 | 0.000000 | 0.327231 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | ... | 0.000000 | 0.282590 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 |
| 1 | 0.343563 | 0.000000 | 0.000000 | 0.418971 | 0.248559 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | ... | 0.418971 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.418971 | 0.000000 | 0.000000 | 0.000000 | 0.000000 |
| 2 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.236607 | 0.398826 | 0.000000 | 0.000000 | 0.398826 | 0.000000 | ... | 0.000000 | 0.204329 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.398826 | 0.000000 | 0.000000 |
| 3 | 0.000000 | 0.355931 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.355931 | 0.000000 | 0.000000 | 0.246415 | ... | 0.000000 | 0.182353 | 0.000000 | 0.355931 | 0.291868 | 0.000000 | 0.355931 | 0.000000 | 0.000000 | 0.355931 |
| 4 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.350859 | ... | 0.000000 | 0.259643 | 0.506793 | 0.000000 | 0.415577 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 |
| 5 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.284104 | 0.000000 | 0.000000 | 0.478888 | 0.000000 | 0.331540 | ... | 0.000000 | 0.490694 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.478888 | 0.000000 |
6 rows × 28 columns
svd = TruncatedSVD(n_components=2);
P = svd.fit_transform(Tfidf_encoding)
color = ['m', 'g', 'r', 'c', 'b','k']
patches = []
for i,texto in enumerate(textos):
plt.plot(P[i,0], P[i,1], color[i]+"o")
patches.append(mpatches.Patch(color=color[i], label='t'+str(i)))
plt.legend(handles=patches)
plt.xlabel('dimension 1')
plt.ylabel('dimension 2')
plt.show()

df1.comp1.sort_values(ascending=False).head(5)
potro 0.478992 juan 0.349054 martin 0.349054 cine 0.296467 tandil 0.249999 Name: comp1, dtype: float64
df2.comp2.sort_values(ascending=False).head(5)
angel 0.355831 cine 0.320480 nacional 0.292709 cerca 0.217343 tanque 0.217343 Name: comp2, dtype: float64
fig=px.scatter(df,x=comp1,y=comp2,text=df.index)
fig.update_traces(textposition='top center')
En la representación 2D de los textos vemos que hay dos grupos separados: uno que habla escencialmente de cine y otro que habla de tenis.
En un escenario de aprendizaje no supervisado, podríamos encontrar estos grupos mediante un algoritmo de clustering.

Sentiment Analysis¶
| El análisis de sentimientos es una técnica a través de la cual podemos analizar un fragmento de texto para determinar el sentimiento detrás de él.
Combina el aprendizaje automático y el procesamiento del lenguaje natural (NLP) para lograrlo. Podemos pensar este problema como un problema de clasificación, donde las features son generadas con el técnicas de preprocesamiento de texto que vimos la clase pasada. |  |
Sentiment Analysis (sin aprendizaje)¶
Vamos a implementar un algoritmo sencillo para analisis de sentimientos, sin tener que utilizar aprendizaje supervisado. Este es un algoritmo posible de entre muchos otros. Está basado en el lexicon de Gravano, A.; Dell’Amerlina Ríos, Matías G.. "Spanish DAL: A Spanish Dictionary of Affect in Language".
Pueden ver el texto en https://bibliotecadigital.exactas.uba.ar/download/technicalreport/technicalreport_n00001.pdf
Este es un primer algoritmo sencillo, fácil de implementar y que tiene la ventaja de no necesitar un corpus de entrenamiento.
dal = pd.read_csv("https://raw.githubusercontent.com/carabedo/labs/master/data/spanish_dal.csv",sep=";",header=None)
dal.columns = ["lemma","agradable_mean","activo_mean","imaginable_mean","agradable_sd","activo_sd","imaginable_sd"]
Cada palabra fue scoreada por una muestra de 662 personas segun 3 criterios:
- ¿Qué tan agradable es la palabra? (Agradable, ni agradable ni desagradable, desagradable)
- ¿Que tan activa es la palabra? (Activa, ni activa ni pasiva, pasiva)
- ¿Qué tan fácil de imaginar es la palabra? (Fácil, ni fácil ni difícil, difícil)
Para cada palabra se calculó el promedio y desvío de los puntajes que se le dieron
## vemos que cada palabra tiene un rating, que es el promedio de 600 personas votando
## 1,2 o 3 el grado de agadabilidad, activo, o imaginable
dal.sample(5)
| lemma | agradable_mean | activo_mean | imaginable_mean | agradable_sd | activo_sd | imaginable_sd | |
|---|---|---|---|---|---|---|---|
| 1990 | indígena_N | 2.2000 | 2.4000 | 3.0000 | 0.4472 | 0.5477 | 0.0000 |
| 1968 | rutina_N | 1.2000 | 2.2000 | 2.2000 | 0.4472 | 1.0954 | 0.8367 |
| 1893 | crimen_N | 1.0000 | 2.2000 | 2.2000 | 0.0000 | 0.8367 | 0.8367 |
| 2298 | castellano_N | 2.2000 | 2.2000 | 3.0000 | 0.4472 | 0.4472 | 0.0000 |
| 1059 | seco_A | 1.7778 | 1.6667 | 2.3333 | 0.6667 | 0.5000 | 0.7071 |
dal.describe()
| agradable_mean | activo_mean | imaginable_mean | agradable_sd | activo_sd | imaginable_sd | |
|---|---|---|---|---|---|---|
| count | 2880.000000 | 2880.000000 | 2880.000000 | 2880.000000 | 2880.000000 | 2880.000000 |
| mean | 2.228680 | 2.320099 | 2.555909 | 0.422463 | 0.531175 | 0.503166 |
| std | 0.476839 | 0.484943 | 0.426395 | 0.258589 | 0.307606 | 0.360048 |
| min | 1.000000 | 1.000000 | 1.000000 | 0.000000 | 0.000000 | 0.000000 |
| 25% | 2.000000 | 2.000000 | 2.200000 | 0.408200 | 0.447200 | 0.000000 |
| 50% | 2.200000 | 2.400000 | 2.600000 | 0.447200 | 0.547700 | 0.547700 |
| 75% | 2.600000 | 2.800000 | 3.000000 | 0.547700 | 0.836700 | 0.836700 |
| max | 3.000000 | 3.000000 | 3.000000 | 1.095400 | 1.095400 | 1.095400 |
## necesitamos, para cada palabra, lemmatizarla y obtener si es un sustantivo, un adjetivo o un verbo.
## python3 spacy download 'es_core_news_md'
sp = spacy.load('es_core_news_md')
## algo así:
for token in sp("El perro verde corre feliz"):
print(token.text, token.pos_)
El DET perro PROPN verde PROPN corre VERB feliz ADJ
## pero ahora, si no es ni adjetivo, ni sustantivo, ni verbo la eliminamos. Si no, la lemmatizamos
def preprocesar_texto(texto,sp,retener= ["NOUN","ADJ","VERB"]):
ans = []
for token in sp(texto):
if token.pos_ in retener:
ans.append(token.lemma_ + "_" + token.pos_[0])
return ans
preprocesar_texto("El perro verde corre feliz",sp)
['correr_V', 'feliz_A']
En el trabajo muestran un algoritmo básico para hacer scores para un texto:
score ← 0
count ← 0
for each word w in T (counting repetitions):
if w is included in Lex:
score ← score + Lexd(w)
count ← count + 1
return score/count
## veamos como funciona
calcular_score(""" me cai y lastime las rodillas, me dijeron que tengo que hacer reposo""",sp,dal)
2.35
calcular_score(""" la comida estuvo rica, le faltaba un poco de sal nada mas""",sp,dal)
2.45
calcular_score( 'no hay problemas, el telefono funciona',sp,dal)
problema_N 1.2 funcionar_V 2.625
1.9125
calcular_score('el problema: el telefono no funciona',sp,dal)
problema_N 1.2 funcionar_V 2.625
1.9125
## veamos como funciona
calcular_score(""" Me parece que es un excelente curso, destacando la dedicación y experiencia de los docentes
así como la calidad del material""",sp,dal)
parecer_V 2.4 excelente_A 3.0 curso_N 2.1111 destacar_V 2.6 experiencia_N 2.8 calidad_N 2.6 material_N 2.2
2.530157142857143
calcular_score("""La realidad es que no estoy pudiendo aprovechar el curso, los docentes no explican con claridad,
no dan buen material para entender como realizar las prácticas. """,sp,dal)
realidad_N 2.3333 aprovechar_V 2.4 curso_N 2.1111 explicar_V 2.6 claridad_N 2.8 dar_V 2.8 material_N 2.2 entender_V 3.0 realizar_V 2.6 práctica_N 2.6
2.5444400000000003
# Podriamos mejorar esto propagando negaciones, entender es un 3, podriamos hacer que no_entender fuese un 1.
otra libreria que tambien usa un lexicon¶
https://github.com/FernanOrtega/SentiLeak
https://colab.research.google.com/drive/1NwW7XZx6_0PcIvL5Mpv0nykD5yuDrtZK#scrollTo=QK15omSoi2O5
Clasificación¶
En esta clase analizaremos un dataset de reviews de celulares en amazon predecir a partir del texto del comentario si la calificación otorgada por el usuario es positiva o negativa.
### Datos
import pandas as pd
df=pd.read_csv('amazon.csv')
from sklearn.model_selection import train_test_split
# Split data en sets de training y test
X_train, X_test, y_train, y_test = train_test_split(df['Reviews'],
df['Positivos'],
random_state=0,
stratify=df['Positivos'])
CountVectorizer¶
from sklearn.feature_extraction.text import CountVectorizer
# Fiteamos el CountVectorizer a los datos de entrenamiento
vect = CountVectorizer().fit(X_train)
len(vect.get_feature_names())
19446
# transformamos los documentos del training set a una matriz de documentos-términos:
X_train_vectorized = vect.transform(X_train)
X_train_vectorized
<23052x19446 sparse matrix of type '<class 'numpy.int64'>' with 607398 stored elements in Compressed Sparse Row format>
from sklearn.linear_model import LogisticRegression
# Entrenamos el modelo
model = LogisticRegression(max_iter=2500)
model.fit(X_train_vectorized, y_train)
LogisticRegression(max_iter=2500)
from sklearn.metrics import roc_auc_score
# Hacemos las predicciones sobre el set de testeo:
predictions = model.predict(vect.transform(X_test))
print('AUC: ', roc_auc_score(y_test, predictions))
AUC: 0.8927592965163733
# Obtenemos los nombres de las features como un array de numpy
import numpy as np
feature_names = np.array(vect.get_feature_names())
# Ordenamos a los coeficientes del modelo
sorted_coef_index = model.coef_[0].argsort()
# Observamos a los 10 coeficientes más grandes y más chicos:
print('Coefs menores:\n{}\n'.format(feature_names[sorted_coef_index[:10]]))
print('Coefs mayores: \n{}'.format(feature_names[sorted_coef_index[:-11:-1]]))
Coefs menores: ['junk' 'worst' 'terrible' 'garbage' 'sucks' 'slow' 'defective' 'poor' 'sucked' 'disappointed'] Coefs mayores: ['excelente' 'excellent' 'excelent' 'love' 'loves' 'perfectly' 'perfect' 'exactly' 'great' 'amazing']
print(model.predict(vect.transform(['not an issue, phone is working',
'an issue, phone is not working'])))
[0 0]
TfIdf¶
from sklearn.feature_extraction.text import TfidfVectorizer
# Fiteamos el TfidfVectorizer al set de entrenamiento definiento un min_df_min=5
vect = TfidfVectorizer(min_df=5).fit(X_train)
len(vect.get_feature_names())
5419
X_train_vectorized = vect.transform(X_train)
model = LogisticRegression()
model.fit(X_train_vectorized, y_train)
predictions = model.predict(vect.transform(X_test))
print('AUC: ', roc_auc_score(y_test, predictions))
AUC: 0.8862895553580062
# Vemos que el modelo no puede predecir bien los siguientes ejemplos:
print(model.predict(vect.transform(['not an issue, phone is working',
'an issue, phone is not working'])))
[0 0]
feature_names = np.array(vect.get_feature_names())
sorted_coef_index = model.coef_[0].argsort()
print('Coefs menores:\n{}\n'.format(feature_names[sorted_coef_index[:10]]))
print('Coefs mayores: \n{}'.format(feature_names[sorted_coef_index[:-11:-1]]))
Coefs menores: ['not' 'slow' 'disappointed' 'doesn' 'worst' 'terrible' 'waste' 'return' 'poor' 'never'] Coefs mayores: ['great' 'love' 'excellent' 'good' 'perfect' 'best' 'awesome' 'easy' 'amazing' 'far']
n-gramas¶
# Fiteamos el CountVectorizer al set de training especificando una min_df=5 y
# extrayendo 1-gramas and 2-gramas
vect = CountVectorizer(min_df=5, ngram_range=(1,2)).fit(X_train)
X_train_vectorized = vect.transform(X_train)
len(vect.get_feature_names())
28611
model = LogisticRegression(max_iter=5000)
model.fit(X_train_vectorized, y_train)
predictions = model.predict(vect.transform(X_test))
print('AUC: ', roc_auc_score(y_test, predictions))
AUC: 0.9092520677698237
feature_names = np.array(vect.get_feature_names())
sorted_coef_index = model.coef_[0].argsort()
print('Coefs menores:\n{}\n'.format(feature_names[sorted_coef_index[:10]]))
print('Coefs mayores: \n{}'.format(feature_names[sorted_coef_index[:-11:-1]]))
Coefs menores: ['junk' 'no good' 'poor' 'sucks' 'not good' 'defective' 'slow' 'garbage' 'broken' 'terrible'] Coefs mayores: ['excellent' 'excelente' 'excelent' 'perfect' 'great' 'love' 'no problems' 'not bad' 'awesome' 'amazing']
print(model.predict(vect.transform(['not an issue, phone is working',
'an issue, phone is not working'])))
[1 0]
En español?¶
https://github.com/sentiment-analysis-spanish/sentiment-spanish
The function sentiment(text) returns a number between 0 and 1. This is the probability of string variable text of being "positive". Low probabilities mean that the text is negative (numbers close to 0), high probabilities (numbers close to 1) mean that the text is positive. The space in between corespond to neutral texts.sentimental.sentiment("""La realidad es que no estoy pudiendo aprovechar el curso, los docentes no explican con claridad,
no dan buen material para entender como realizar las prácticas. """)
2.878155459048572e-06
sentimental.sentiment(""" Me parece que es un excelente curso, destacando la dedicación y experiencia de los docentes
así como la calidad del material""")
0.04347740188229433
Por que no anda bien?¶
sentiment-spanish
How does it work?
sentiment-spanish is a python library that uses Naive Bayes classification to predict the sentiment of spanish sentences. The model was trained using over 800000 reviews of users of the pages eltenedor, decathlon, tripadvisor, filmaffinity and ebay. This reviews were extracted using web scraping with the project opinion-reviews-scraper
Word Embeddings¶
Modelo semántico del lenguaje que busca mapear la alta dimensionalidad del lenguaje natural en un espacio de baja dimensionalidad intentando retener la mayor cantidad de informacion semantica.
Busca:
- Encontrar similitud semántica entre palabras y entre documentos
- Operar con embeddings (en el espacio reducido) y buscar la palabra más cercana (en el espacio completo).
Para que sirve?:
- Autocompletar frases
- Text summarization: resumir textos
- Sentiment Analysis
- Traductores: neural machine translation
- Chatbots

Pero que es un embedding?¶
Un mapeo, una matriz que te devuelve la posicion en un espacio de baja dimensionalidad (N=300) de cualquier palabra.

Podemos visualizar ese espacio?¶

Operaciones en el embedding, significan algo en el espacio real?¶

Y como lo armo?¶

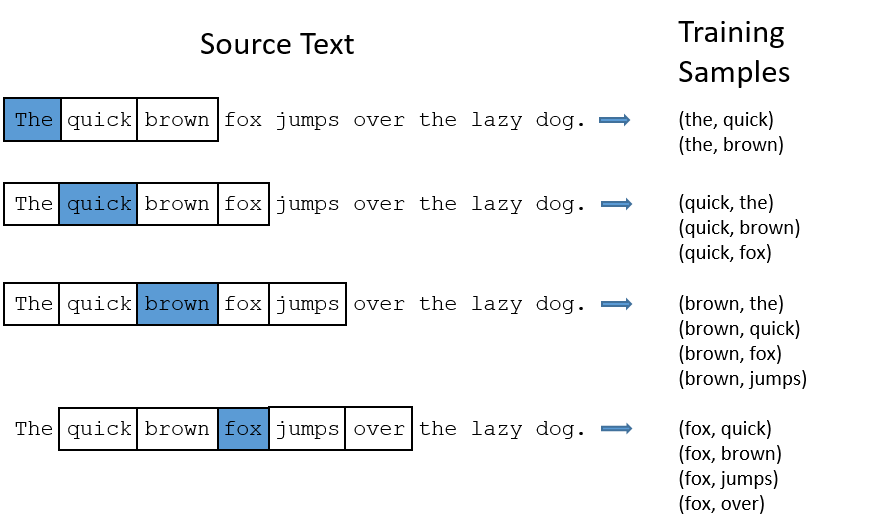
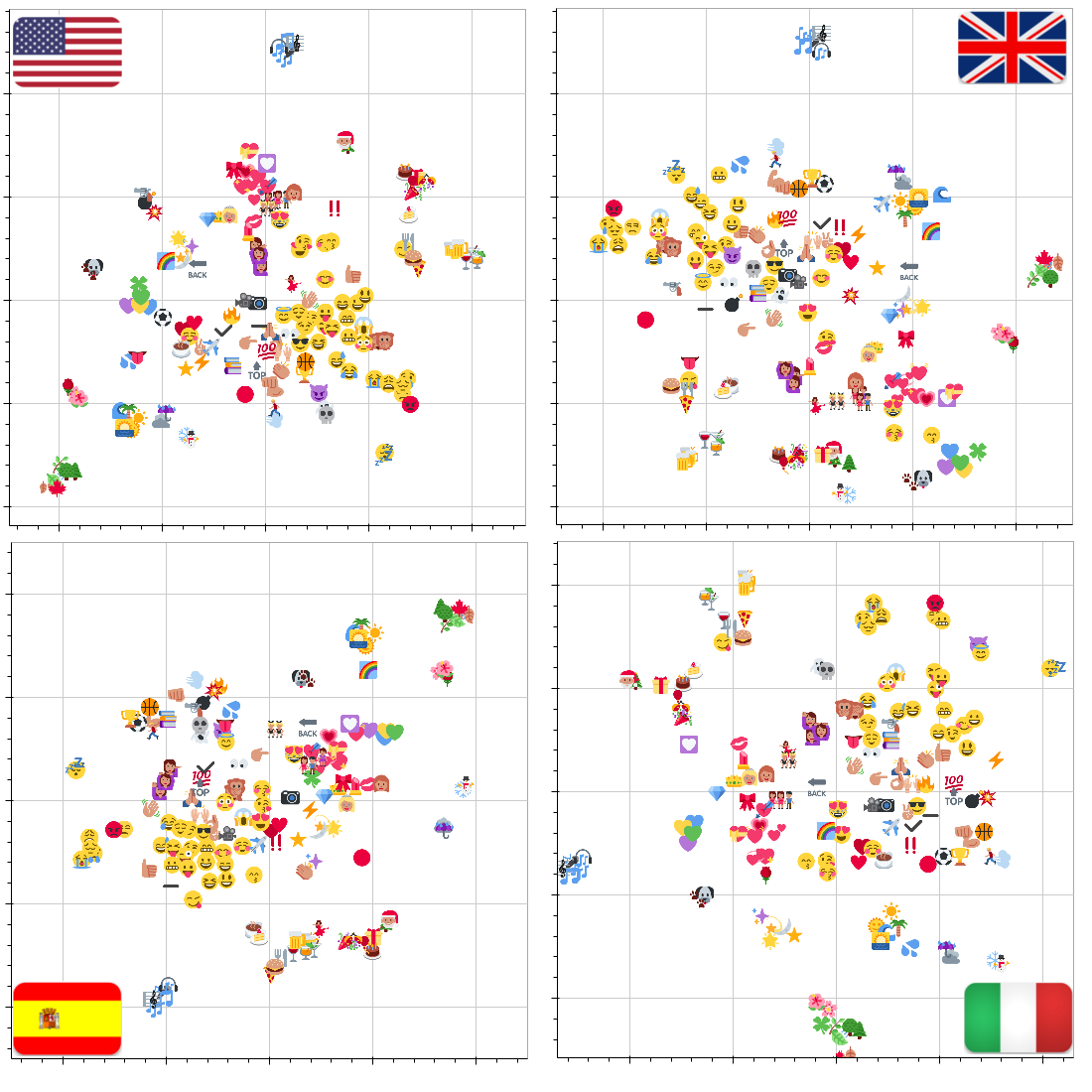
Construimos un modelo de clasificación de textos empleando los algoritmos que ya conocíamos.
Construimos el conjunto de features del modelo transformando los inputs (textos) mediante las técnicas de preprocesamiento que vimos en la clase pasada.
Evaluamos la performance del modelo del mismo modo que lo hacemos con cualquier modelo de clasificación.